
PDFをテキスト変換するツールは多数出ていますが、テキストのOCR機能が足りないのかそもそも完璧なものが少ない印象です。
オンライン、オフライン等問わず試した限りでしっくり来るものがないため、Adobe Acrobat PROなどの王道を進むのが現状ではベストプラクティスだと思っています。しかも、マクロに近いアクションウィザードがあるのでそれを使って出来るならそうすべきというところです。(Standard版だとアクションウィザードはないっぽいですが)
一方で一時的または短期的で費用をかけたくない場合どうするか。アイデアが問われるのですがそのあたり考えてみました。
結論
現時点ではということですが、
- PDF作成時において埋め込みフォントで作成していないと、PDF→テキスト化が文字化けする(フォント情報がないため)
- 埋め込みフォントPDFであれば正しくテキスト化できる
- 埋め込みフォントでないPDFしかない場合は画像OCR等(OnlineOCR的なもの)で試すのがベストプラクティスか
というところです。いやー、勉強になりました。
間違っていたりそれは違うかもというのがあればお気軽に教えて下さいませ。
PDF作成とくにテキスト化の検証
PDF作成自体は、一昔前はそれほどなかったのですが、CubePDF等さくっと使えるものが多く出てきました。印刷機能を用いて簡単にPDFができます。標準Windows機能でもあったかもしれませんが、大分こなれてきましたよね。
上のCubePDFUtilityがページ編集機能があるもののテキスト抽出系は出来ません。抽出という機能も「ページを別のPDFに保存」ということで求めるものではありません。既存パッケージソフトで海外系ソフトなど出てきますがどれも似たより寄ったりという印象です。国内のもですね。
オンラインサービス(Webサイト)などで、アップロードするとテキスト抽出が出来るサービスがあります。OnlineOCRは対応言語に日本語があり、テキスト/Word/Excelに変換出来ます。元ファイルは、PDFをはじめ、JPG等画像ファイルもいけます。
一時期PDF変換する時に使わせてもらってたのですが、1時間15ページまで無料でその枠を超えて使うために課金利用をしたことがあります。その時の不満としては、正確に変換できない(エラー)だったりする時でもカウントされる(課金ポイントを使うため)ことですかね。正確に変換とはテキスト精度でなく、ファイルが生成されないなどというイメージです。というのもあり最近使っていません。もう一言いえば、PDFの変換精度がなぜか著しく悪くなり使用に耐えられなかったという点もあります。なので結果的にほとんど使わなくなりました。
では全然使えないかというとそういうことではなく、使い所なのではないか、要するにPDFの内容、レイアウト自体かなと。そういう意味では都度選択肢として検討しても良いかも知れません。
本ブログ記事のキャプチャ画像PNGで変換を試してみる
余興としてやってみましょう。スクショを撮ったものをPNG形式で保存しました。これを上のOnlineOCRにアップロードして、言語はJAPANESEで、アウトプット形式はText Plainにしてみます。

以下が出力後のイメージです。
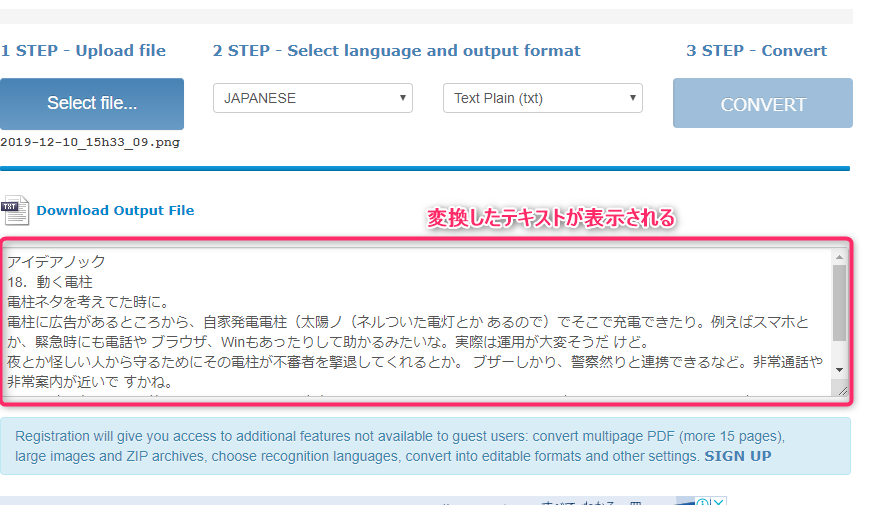
テキストエリアに変換されたファイルが出来ています。元の日本語が変(笑)というのもありますが、変換結果としては、 太陽パネル、Wifiなどの単語で誤認識って感じですかね。妙なスペースがたまに入ったりもします。
とはいえそれ以外は概ねいけるので、テキストを占める量とか、言語が占める割合とかかもしれませんね。ご参考まで。
Xpdf等フリーソフトを使う
フリーソフトとはいえコマンドラインから使うものからGUI形式まで幅広くあるような印象です。ですが、結果的にOCR機能(画像をテキストにする機能)で決まると思うのでその大差はないような気がします。OCR機能を独自開発しているなら別ですが、かなり限られるか一部の大手かGoogle等かスタートアップくらいしかないのかなと勝手に思っています。
Xpdfはコマンドラインツールもあるのでそれを使うことでコマンドラインから付属するpdftotext.exeを使うことでテキスト化が出来るとあります。Xpdf:コマンドラインのPDFツールなどが詳しいのでおすすめです。
余興でこちらも遊んでみましょう。
当ブログの記事先ほどと同様の部分を印刷→CubePDFでPDF化します。そのPDFファイルを、Xpdfからコマンドラインでテキスト化してみます。
Xpdfのコマンドラインは例えば
C:\pdftotext -enc Shift-JIS test.pdfみたいな感じでやっています。
Shift-JIS結果、UTF-8結果ともに変わらないですが、テキストで貼り付けたらWordpressの動きがおかしくなったかもなので、画像です(笑)

うーん、これは使えないですね。なんかあったというくらいしかありませんね。ちなみにXpdfは言語対応もしているのでJapaneseもいけるはずですが、まあものによるのでしょうか。ミスってたらすいません。
ダメ元で先のPDFを「Adobe Acrobat Reader DC」でテキスト保存してみると、
実際にPDFテキストによっては、いけるものもあると思っているのでそもそものPDF作成時でAcrobatで作ってないと駄目なのかもしれないと本質的なことを思いました。なかなか厳しい結果ですが、要はOCR化してテキスト化はこれだけでは出来ないよって判断になります。残念ですが。
そこで気を取り直して、手元のWordにブログ文書を貼り付け(プレーンテキスト)、PDF保存してみました。それを再度Xpdfでpdftotextすると・・・

おおー。これは使えそうです。
気になったのはこの時のPDF、つまりWordから作ったPDFは「テキスト保存」でも「CTRL+A」で全選択してテキストエディタに貼り付けしても同様の結果でした。つまり、このことからCubePDFを悪者にするわけではないですが、そもそも印刷したアウトプット時点でテキストっぽい情報は失われて画像状態、バイナリ状態になっているのかなと推測できそうです。
PDF自体に何か違いがあるか?ですが、以下を比較したところ明確なのは、フォントの埋め込み情報が違う、PDF変換情報にiTextSharp(TM)などが入っているの違いです。
フォントの埋め込みはそのフォントがなければ正しく文字(画像としては文字通り見える)として扱えません。それで文字化けしているのではないかと推測できます。
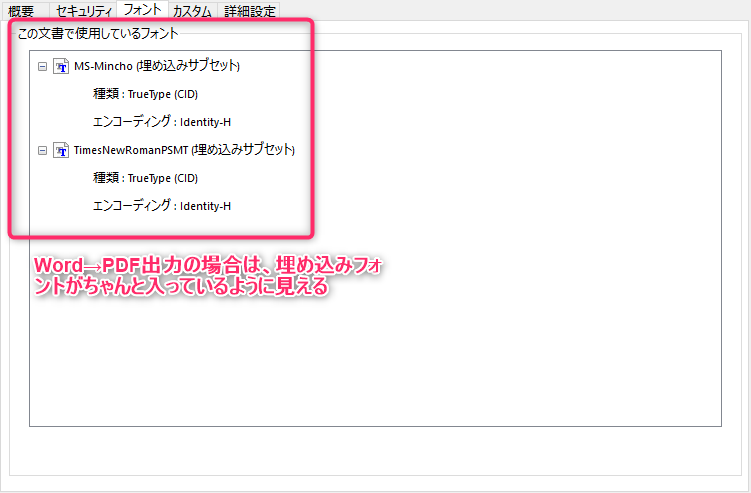
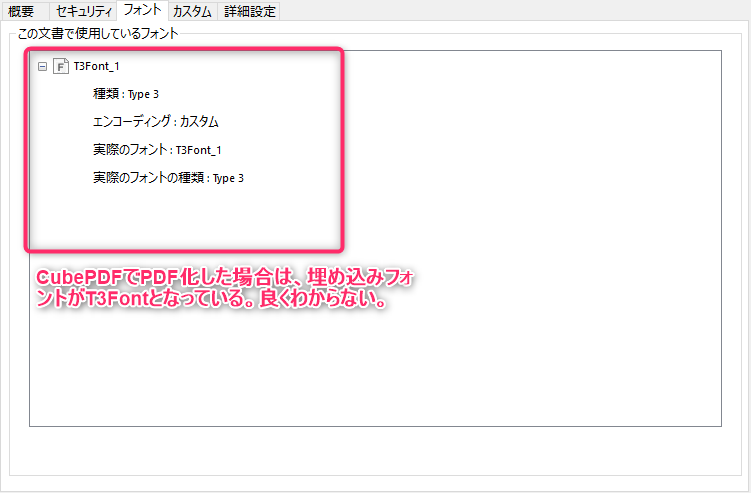
T3Fontとは何かは例えばpdf ファイルのフォント埋め込みについてによれば、おそらくPostScriptType3略してT3ではないかと思われます。この挙動がどうかはちょっと分からないです。
CubePDFのマニュアルを読むと、プリンタ設定画面の印刷設定→詳細設定でPostScriptオプションがあります。これは自動になっていたので、あえて「Natibe TrueType」としてフォント情報を拾ってくれないかなと思い再度試してみましたが、文字化けは変わらず、T3フォントで認識されました。他のアウトラインやビットマップはフォントではなくなるので試していません。
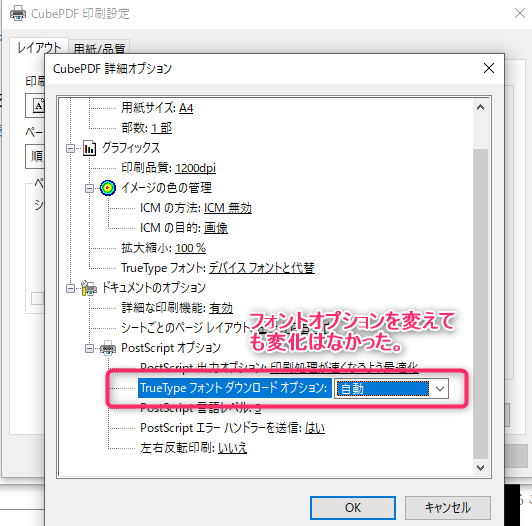
Xpdfの話じゃなかったのかと話が飛びましたが戻します。つまり、Xpdfが悪いのでなく、元のフォントが埋め込まれてないPDFが悪かったといえそうです。
ということは、PDF自体しか手元にないとこの作戦は使えませんが、元ファイル→PDF化しているならば再度検討するのはありかもしれませんね。
Googleドキュメントはどうか?
Google等オンラインサービスはどうかというところです。分かりやすいのはPDFファイルをGoogleドライブにアップロードしてGoogleドキュメントで開くとテキスト化されているかどうかを見ることです。
検証結果からいうと、先程のPDF埋め込みなら正常、そうでないなら文字化けしていました。
ほぼほぼオッケーという感じですね。ここで明確になったのは、埋め込みフォントPDFを作れるものでPDFを作ろうってことですかね。
大分すっきりしました。
おわりに
PDFをテキスト変換するというシーンは限られていそうでありながら、実はPDF自体はスタンダードに出回っておりわりと標準です。しかしそのPDFを加工するや編集するとなると大変。みたいなものがまだまだありそうです。
ちなみにさらっと書いていますが、PDFしか手元にない場合は、埋め込みフォントがないPDFなら変換はできません。悲しいですが、例えばですが、PDF自体を画像として出力してその画像にある文字をOCRするみたいな、これも遠回りかもしれませんがもしかしたら出来るかもしれません。ただそれは、OCRとか画像テキスト変換の話になってきてちょっと手こずりそうなのと、難しそうというところで調べきれていません。
実際はOnlineOCRでPNGがそこそこOCR出来てテキスト化できるので、そこからなんとかできないかというところかもしれませんね。
ものすごくざっくりまとめると、
PDFが埋め込みフォントあり→テキスト化はXpdf等で自動化可能。
PDFが埋め込みフォントなし→画像ファイル化してOnlineOCRで頑張る。
みたいな形です。ここらへんもっとスマートにできればいいのですが、当然自動化するとファイル数や処理数が多いので、GUIや1件ずつやってられないので後者でひっかかるのは画像ファイル化ですよね。これ一個ずつやってたらだめなので、PDFファイルからどう画像化して取り出すか。これは次の課題となりそうですね。

